Anniversaries are strange: no one but those involved have any reason to even know they exist, which makes them easy to skip; for example, last year I mostly ignored the 10 year anniversary of starting Stratechery because I was more eager to write about ChatGPT Getting a Computer. That leaves today, April 16, as my last chance to mark a tin anniversary: ten years ago Stratechery added a subscription option, making this my full-time job.
It was, for the record, a miserable day: I had a convoluted plan to offer different site experiences for subscribers and non-subscribers: the former would receive daily linked-list updates (a la Daring Fireball) while the latter would still have access to longer-form Articles; I scrapped the concept two days later in favor of simply sending subscribers a daily email, and so the paid newsletter model was born.
That accident of history ended up being why this anniversary is actually more meaningful to me: while I am most well-known for Stratechery, I am equally proud of the paid newsletter model — services like Substack were based on Stratechery — and gratified that so many writers are making a living connecting directly with readers.
Of course newsletters aren’t the only medium where this happens (and, in fact, I’ve never viewed Stratechery as a newsletter; it’s a blog that you can read via email); there are also podcasts (which Stratechery has expanded into) and YouTube (like and subscribe to the Stratechery and Sharp Tech channels!). The king of the latter, at least when it comes to tech, is Marques Brownlee, aka MKBHD.
The Humane AI Pin
Humane introduced the wearable AI Pin at a TED Talk 11 months ago, painting the vision of a future without screens, powered by AI. I was, for the record, pretty skeptical: most new tech categories layer on top of what came before, as opposed to outright replacing them; Humane’s proposal of a wearable device that was completely independent of the phone in your pocket seemed unlikely to succeed. Still, I was cheering for them: I applaud any company trying to build something new, and AI provides the opening for new experimentation.
Unfortunately, last week the reviews of the AI Pin came out and they were universally terrible; The Verge’s headline summed up the sentiment: Humane AI Pin review: not even close. David Pierce wrote:
I came into this review with two big questions about the AI Pin. The first is the big-picture one: is this thing… anything? In just shy of two weeks of testing, I’ve come to realize that there are, in fact, a lot of things for which my phone actually sucks. Often, all I want to do is check the time or write something down or text my wife, and I end up sucked in by TikTok or my email or whatever unwanted notification is sitting there on my screen. Plus, have you ever thought about how often your hands are occupied with groceries / clothes / leashes / children / steering wheels, and how annoying / unsafe it is to try to balance your phone at the same time? I’ve learned I do lots of things on my phone that I might like to do somewhere else. So, yeah, this is something. Maybe something big. AI models aren’t good enough to handle everything yet, but I’ve seen enough glimmers of what’s coming that I’m optimistic about the future.
That raises the second question: should you buy this thing? That one’s easy. Nope. Nuh-uh. No way. The AI Pin is an interesting idea that is so thoroughly unfinished and so totally broken in so many unacceptable ways that I can’t think of anyone to whom I’d recommend spending the $699 for the device and the $24 monthly subscription.
Brownlee agreed; he said at the start of his YouTube review:
So this is the Humane AI Pin. It is a brand new product in a really interesting new form factor of an ultra-futuristic wearable computer. In a time of all these crazy gadgets and Vision Pro and wearable glasses, it’s so sick that we get so many genuinely new first generation products like this to give a shot.
Unfortunately it’s also the new worst product I think I’ve ever reviewed in its current state. There’s just so many things bad about it. It’s so bad, in fact, that I actually think it’s kind of distracting to understand what the point of the device is as we go through it, so I’m going to have to separate it out for this video. First, I’m going to tell you what it is and what it’s supposed to do, and then I’ll tell you what my experience has actually been using it.
Brownlee proceeded to do just that: he presented Humane’s vision, detailed how poorly it lived up to it (including the probably fatal flaw inherent in its decision to pretend smartphones don’t exist), and granted that future software updates might improve the experience. I thought it was a fair,1 if brutal, review, but what had some people up in arms was the title and thumbnail:
I find it distasteful, almost unethical, to say this when you have 18 million subscribers.
Hard to explain why, but with great reach comes great responsibility. Potentially killing someone else’s nascent project reeks of carelessness.
First, do no harm. pic.twitter.com/xFft3u2LYG
— Daniel Vassallo (@dvassallo) April 15, 2024
I don’t tweet much these days — if you want one of my tips for lasting over a decade, that is one of them, for my own peace of mind more than anything — but Vassallo’s sentiment bothered me enough to fire off a response:
Marques’ reach is a function of telling the truth. He didn’t always have 18 million subscribers, but he had his integrity from the beginning. Expecting him to abandon that is the only thing that is “distasteful, almost unethical”. https://t.co/UysMnuIctS
— Ben Thompson (@benthompson) April 15, 2024
I honestly think I had this anniversary on my mind: I remember when I first started, with only a few hundred followers on Twitter, armed with nothing but my honest takes about tech; my only hope was that those takes would be original enough and valuable enough to build an audience. That they were didn’t diminish the desire to be honest; indeed, one of the biggest challenges creators face as they grow is retaining their edge even when they know people are actually paying attention to what they have to say.
MKBHD’s Responsibility
The more interesting Vassallo tweet, though, and the one that inspired this Article, was this exchange in response to his original tweet:
MKBHD is not the market. He *significantly* influences the market.
If a single person can affect the stock price of a company, we usually restrict what they can say or when. MK should be cognizant of the unconstrained power he has (for now).
— Daniel Vassallo (@dvassallo) April 15, 2024
Ignore the vaguely threatening “for now” ; Vassallo is touching on something profound about Brownlee, that I myself understand intimately: what the Internet has made uniquely possible is total loyalty to your customers, and that is threatening.
Let me start with myself: every dollar of income I have comes from my subscribers,2 all of whom pay the same price.3 If someone doesn’t like what I write, I make it easy to unsubscribe; if they accuse me of writing for favor or illegitimate profit I am happy to unsubscribe them myself, and refund their money. After all, to use Brownlee’s reponse to Vassallo:
We disagree on what my job is
— Marques Brownlee (@MKBHD) April 15, 2024
My job is to make my subscribers happy, and the best way I’ve found to do that is to stay as true as I can to what I set out to do in the beginning: write things that are original and valuable. When I succeed I’m happy, and the numbers take care of themselves; when I publish something I’m not happy with, I have trouble sleeping. When tech companies or investors or anyone else is mad, I am free to not pay them any attention.
Brownlee, though, is, to Vassallo’s point, something else entirely: 18 million subscribers is an incredible number, even if only — “only” — 3.5 million people have viewed his Humane video. If Humane’s AI Pin wasn’t already dead in the water, it’s fair to say that @levelsio is right:
MKBHD just delivered the final blow to the Humane pin pic.twitter.com/cW9CnRkdPF
— @levelsio (@levelsio) April 15, 2024
Who, though, is to blame, and who benefited? Surely the responsibility for the Humane AI Pin lies with Humane; the people who benefited from Brownlee’s honesty were his viewers, the only people to whom Brownlee owes anything. To think of this review — or even just the title — as “distasteful” or “unethical” is to view Humane — a recognizable entity, to be sure — as of more worth than the 3.5 million individuals who watched Brownlee’s review.
This is one of the challenges of scale: Brownlee has so many viewers that it is almost easier to pretend like they are some unimportant blob. Brownlee, though, is successful because he remembers his job is not to go easy on individual companies, but inform individual viewers who will make individual decisions about spending $700 on a product that doesn’t work. Thanks to the Internet he has absolutely no responsibility or incentive to do anything but.
Media and the Internet
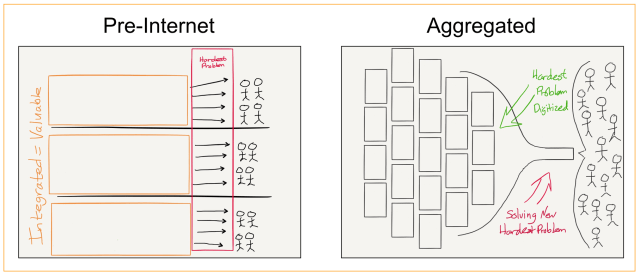
While Stratechery mostly covers tech, I also spend a lot of time on media; in the early days of Stratechery, this mostly meant newspapers, and my argument was that was in fact a particularly useful angle on the impact of technology broadly: the fact that newspapers were text meant that they felt the impact of the Internet almost immediately, effects that would, as devices became more powerful and ubiquitous, and broadband faster and more reliable, impact everything. And, of course, Stratechery was a written product, so I had a stake in the game.
To that end, I wrote a series of Articles in the run-up to April 16, 2014, laying the groundwork for why I thought my subscription offering would work. The last of these was entitled Newspapers Are Dead; Long Live Journalism, where I wrote:
Remember how the New York Times was started as a means of making money? After the first year the paper had a circulation of 26,000 in a city of over half a million, but had incurred up-front capital costs of $50,000, and first-year expenses of $78,000 (In 1851 dollars; the modern equivalent would be $1.4 million and $2.2 million respectively). Compare that to this blog (which, by happy coincidence, turns one year old tomorrow, making this comparison timely): FiveThirtyEight and the End of Average, the first article in this series, has been read by over 30,000 people; meanwhile, I’ve spent less than $2,000. More readers, way less money.
You may consider the comparison unfair — an entire newsroom putting out a daily edition as compared to a solo blogger posting one Article — but the unfairness is the point. No one shared my article because it was from Stratechery, but then again, no one shares an article today just because it’s from the New York Times; all that matters is the individual article and its worth to the reader and potential sharer. As a writer, this is amazing. When it comes to reader attention, I am competing on an equal footing with The New York Freaking Times! Unfortunately for The New York Times, when it comes to making money they’re competing with Google and Facebook. Most distressingly, though, when it comes to costs, they’re competing with the last 150 years. Everything from printing presses to sales and marketing is deadweight if advertising is not a sustainable model.
The New York Times has, to its immense credit, figured out how to go direct to readers; most other newspapers have struggled: cost structures that were predicated on owning printing presses and delivery trucks simply don’t make sense in a world where distribution is free.
Free distribution, meanwhile, made Stratechery possible: I just needed to write compelling content on my own website. Brownlee, meanwhile, got his free distribution from YouTube (and, to the extent you want to complain about his accurate but attention-grabbing headline, the realities of the YouTube algorithm, the one non-viewer incentive Brownlee needs to respond to, looms large). The key point is that he could do everything else on his own, starting with the webcam on his HP Pavilion laptop that he used to record his first video:
Today Brownlee has a top-of-the-line studio and a staff, but the fundamental principle remains: in media one person can do it all, and build a thriving business that makes everyone from Humane to Apple care deeply about what he or she has to say — far more than they care about any traditional publication.
AI and Intelligence
I mentioned at the beginning that last year I wrote about ChatGPT Gets a Computer in lieu of an anniversary post; that Article, which was built around OpenAI’s announcement of (now-discontinued) ChatGPT plugins, was about the nature of the brain and how large learning models did or did not compare.
Computers are deterministic: if circuit X is open, then the proposition represented by X is true; 1 plus 1 is always 2; clicking “back” on your browser will exit this page. There are, of course, a huge number of abstractions and massive amounts of logic between an individual transistor and any action we might take with a computer — and an effectively infinite number of places for bugs — but the appropriate mental model for a computer is that they do exactly what they are told (indeed, a bug is not the computer making a mistake, but rather a manifestation of the programmer telling the computer to do the wrong thing).
I’ve already mentioned Bing Chat and ChatGPT; on March 14 Anthropic released another AI assistant named Claude: while the announcement doesn’t say so explicitly, I assume the name is in honor of the aforementioned Claude Shannon. This is certainly a noble sentiment — Shannon’s contributions to information theory broadly extend far beyond what Dixon laid out above — but it also feels misplaced: while technically speaking everything an AI assistant is doing is ultimately composed of 1s and 0s, the manner in which they operate is emergent from their training, not proscribed, which leads to the experience feeling fundamentally different from logical computers — something nearly human — which takes us back to hallucinations; Sydney was interesting, but what about homework?
I added in an August Update:
The point of that Article was that ChatGPT’s plugin architecture gave hallucinating creative LLMs access to determinative computers to ascertain truth, not dissimilar to the way a creative being like you or I might use a calculator to solve a math problem. In other words, the LLM is the interface to the source of truth, not the source of truth itself.
That is exactly what this “coming soon” feature is all about: you don’t make an LLM useful for your business by adding your business’s data to the LLM; that is simply a bit more text in a sea of it. Rather, you leverage the LLM as an interface to “computers” that deterministically give you the right answer. In this case, those computers will be “connecting the applications you already have”, which sounds to me an awful lot like enterprise-specific plug-ins.
The specifics of product implementations are not the point, but rather the distinction between a natural language interface based on probabilities and computers based on deterministic calculations; I think using the former to access the latter will remain one of the most important applications of large language models.
There is, though, one more piece: who actually tells the AI what to do, such that it needs access to a computer of its own? In ChatGPT Gets a Computer, which analogized large language models to Jeff Hawkin’s theory of the brain, I expressed hope that the beliefs he expressed about the nature of intelligence in A Thousand Brains: A New Theory of Intelligence extended to large language models. Hawkins writes:
Intelligence is the ability of a system to learn a model of the world. However, the resulting model by itself is valueless, emotionless, and has no goals. Goals and values are provided by whatever system is using the model. It’s similar to how the explorers of the sixteenth through the twentieth centuries worked to create an accurate map of Earth. A ruthless military general might use the map to plan the best way to surround and murder an opposing army. A trader could use the exact same map to peacefully exchange goods. The map itself does not dictate these uses, nor does it impart any value to how it is used. It is just a map, neither murderous nor peaceful. Of course, maps vary in detail and in what they cover. Therefore, some maps might be better for war and others better for trade. But the desire to wage war or trade comes from the person using the map.
Similarly, the neocortex learns a model of the world, which by itself has no goals or values. The emotions that direct our behaviors are determined by the old brain. If one human’s old brain is aggressive, then it will use the model in the neocortex to better execute aggressive behavior. If another person’s old brain is benevolent, then it will use the model in the neocortex to better achieve its benevolent goals. As with maps, one person’s model of the world might be better suited for a particular set of aims, but the neocortex does not create the goals.
To the extent this is an analogy to AI, large language models are intelligent, but they do not have goals or values or drive. They are tools to be used by, well, anyone who is willing and able to take the initiative to use them.
AI and the Sovereign Individual
I don’t think either Brownlee or I particularly need AI, or, to put it another way, are overly threatened by it. Yes, ChatGPT would have written several thousands words far more quickly than the hours it took me to write this Article, but I am (perhaps foolishly) confident that they would not be original and valuable enough to take away my audience; I think it’s the same for Brownlee.
The connection between us and AI, though, is precisely the fact that we haven’t needed it: the nature of media is such that we could already create text and video on our own, and take advantage of the Internet to — at least in the case of Brownlee — deliver finishing blows to $230 million startups.
How many industries, though, are not media, in that they still need a team to implement the vision of one person? How many apps or services are there that haven’t been built, not because one person can’t imagine them or create them in their mind, but because they haven’t had the resources or team or coordination capabilities to actually ship them?
This gets at the vector through which AI impacts the world above and beyond cost savings in customer support, or whatever other obvious low-hanging fruit there may be: as the ability of large language models to understand and execute complex commands — with deterministic computing as needed — increases, so too does the potential power of the sovereign individual telling AI what to do. The Internet removed the necessity — and inherent defensibility — of complex cost structures for media; AI has the potential to do the same for a far greater host of industries.
Brownlee’s 2nd most popular video is only two months old: it’s his overview of the Apple Vision Pro; it’s not, if fiction is our guide, an accident that Meta is developing the Quest and Apple has released the Vision Pro just as AI seems poised to threaten an ever-increasing number of jobs. This was the world painted by Pixar’s Wall-E:

It’s funny, because before I looked up this photo, I could have sworn the humans in the film, lulled to insouciance by an AI that addressed all of their physical needs, were wearing headsets; I guess Pixar overestimated our ability to build space-faring cruise ships and underestimated the relentless progression of consumer electronics.
My suspicion, however, is that Pixar got it wrong, and this famous photo of Mark Zuckerberg at Mobile World Congress in 2016 is closer to the truth of the matter.

Wall-E erred by assuming that every human was the same, all gleefully enslaved by AUTO, the ships AI. In fact, though, I suspect humanity will be distributed bi-modally, with the vast majority of people happily wearing their Vision Pros or watching their streaming service or viewing their TikTok videos, while increasingly sovereign individuals, aided by AI, pilot the ship.
That may sound extreme, but again, this is why it is useful to look to media first: Brownlee — one man, who started out by reviewing a media center remote on his HP laptop — does in fact hold the fate of entire companies and products in his hand. My bet is not that AI replaces Brownlee, but that AI means Brownlee’s for everything, not just media.
As for me, I plan on documenting it every step of the way, thanks to every person who has supported Stratechery over the last 10 years, and to whom I alone owe accountability, and gratitude.
Actually, the deference Brownlee gave the vision and the potential of future upgrades was arguably generous ↩
I previously spoke for pay, and even more previously offered consulting, and even more previously than that had ads; however, I ended ads in 2014, consulting in 2015, and haven’t accepted any paid speaking opportunities since 2017. This is all covered on my about page. ↩
$12/month or $120/year for the last five years, increasing to $15/month and $150/year on April 22 ↩

























{kind=link}