
You’ve heard the adage “It’s all 1s and 0s”, but that’s not a figure of speech: the transistor, the fundamental building block of computers, is simply a switch that is either on (“1”) or off (“0”). It turns out, though, as Chris Dixon chronicled in a wonderful essay entitled How Aristotle Created the Computer, that 1s and 0s, through the combination of mathematical logic and transistors, are all you need:
The history of computers is often told as a history of objects, from the abacus to the Babbage engine up through the code-breaking machines of World War II. In fact, it is better understood as a history of ideas, mainly ideas that emerged from mathematical logic, an obscure and cult-like discipline that first developed in the 19th century.
Dixon’s essay — which I’ve linked to previously — is well worth a read, but the relevant point for this article is perhaps a surprising one: computers are really stupid; what makes them useful is that they are stupid really quickly.
The Problem with Processor Vulnerabilities
Last week the technology world was shaken by the disclosure of two vulnerabilities in modern processors: Meltdown and Spectre. The announcement was a bit haphazard, thanks to the fact that the disclosure date was moved up by a week due to widespread speculation about the nature of the vulnerability (probably driven by updates to the Linux kernel), but also because Meltdown and Spectre are similar in some respects, but different in others.
Start with the similarities: the outcome for both vulnerabilities is the same — a non-privileged user can access information on the computer they should not be able to, like secret keys or passwords or any other type of data owned by other users. This is a particularly big problem for cloud services like AWS, where multiple “tenants” use the same physical hardware:
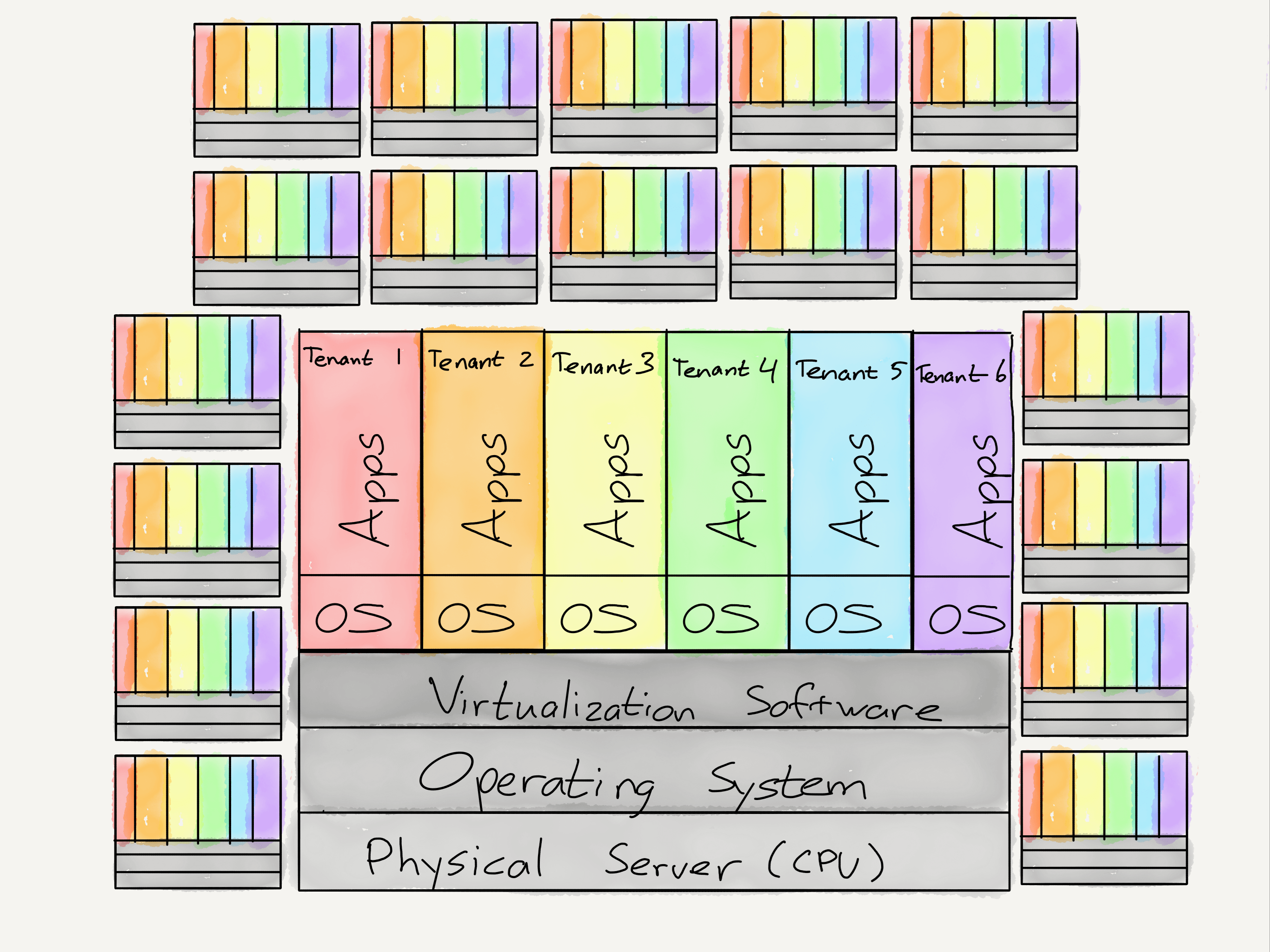
This multi-tenant architecture is achieved through the use of virtual machines: there is specialized software that runs on a single physical computer that allows each individual user to operate as if they have their own computer, when in fact they are sharing. This is a win-win: single-user computers sit idle the vast majority of the time (they are stupid really quickly), but if multiple users can use one computer then the hardware can be utilized far more efficiently. And, in the case of cloud services, that same concept can be scaled up to millions of physical computers sharing even more fundamental infrastructure like cooling, networking, administration, etc.
The entire edifice, though, is predicated on a fundamental assumption: that users in one virtual machine cannot access data from another. That assumption, by extension, relies on trust in the integrity of the virtual machine software, which relies on trust in the integrity of the underlying operating system, which ultimately relies on trust in the processor at the heart of a server. From the Meltdown white paper (emphasis mine):
To load data from the main memory into a register, the data in the main memory is referenced using a virtual address. In parallel to translating a virtual address into a physical address, the CPU also checks the permission bits of the virtual address, i.e., whether this virtual address is user accessible or only accessible by the kernel. As already discussed in Section 2.2, this hardware-based isolation through a permission bit is considered secure and recommended by the hardware vendors. Hence, modern operating systems always map the entire kernel into the virtual address space of every user process. As a consequence, all kernel addresses lead to a valid physical address when translating them, and the CPU can access the content of such addresses. The only difference to accessing a user space address is that the CPU raises an exception as the current permission level does not allow to access such an address. Hence, the user space cannot simply read the contents of such an address.
The kernel is the core part of the operating system that should be inaccessible by normal users; it has its own memory to store not only core system data but also data from all of the users (for example, when it has to be written to or read from permanent storage). Even here, though, the system relies on virtualization — that memory is the same physical memory users utilize for their applications. It is up to the CPU to keep track of what parts of memory belong to whom, and this is where the vulnerabilities come in.
Speculative Execution
I just referenced three critical parts of a computer: the processor, memory, and permanent storage. In fact, the architecture for storing data is even more complex than that:

- Registers are the fastest form of memory, accessible every single clock cycle (that is, a 2.0 GHz processor can access registers two billion times a second). They are also the smallest, usually only containing the inputs and outputs for the current calculation.
- There are then various levels of cache (L1, L2, etc.) that are increasingly slower and, on the flipside, increasingly larger and less expensive. This cache is located in a hierarchy: data that is needed immediately will be moved from the registers to L1 cache, for example; slightly less necessary data will be in L2, then L3, etc.
- The next major part of the memory hierarchy is main memory, that is system RAM. While the amount of cache is dependent on the processor model, the amount of memory is up to the overall system builder. This memory is massively slower than cache, but it is also massively larger and far less expensive.
- The last part of the memory hierarchy, at least on a single computer, is permanent storage — the hard drive. Solid-state drives (SSDs) have made a huge difference in speed here, but even then permanent memory is massively slower than main memory, with the same tradeoffs: you can have a lot more of it at a much lower price.
- While not part of the traditional memory hierarchy, cloud applications often have permanent memory on a separate physical server on the same network; the usual tradeoffs apply — very slow access in exchange for other benefits, in this case keeping data separate from its application.
To be sure, “very slow” is all relative — we are talking about nanoseconds here. This post by Jeff Atwood puts it in human terms:
That infinite space “between” what we humans feel as time is where computers spend all their time. It’s an entirely different timescale. The book Systems Performance: Enterprise and the Cloud has a great table that illustrates just how enormous these time differentials are. Just translate computer time into arbitrary seconds:
1 CPU cycle 0.3 ns 1 s Level 1 cache access 0.9 ns 3 s Level 2 cache access 2.8 ns 9 s Level 3 cache access 12.9 ns 43 s Main memory access 120 ns 6 min Solid-state disk I/O 50-150 μs 2-6 days Rotational disk I/O 1-10 ms 1-12 months Internet: SF to NYC 40 ms 4 years Internet: SF to UK 81 ms 8 years Internet: SF to Australia 183 ms 19 years OS virtualization reboot 4 s 423 years SCSI command time-out 30 s 3000 years Hardware virtualization reboot 40 s 4000 years Physical system reboot 5 m 32 millenia […]
The late, great Jim Gray…also had an interesting way of explaining this. If the CPU registers are how long it takes you to fetch data from your brain, then going to disk is the equivalent of fetching data from Pluto.

Gray presented this slide while at Microsoft, to give context to that that “Olympia, Washington” reference. Let me extend his analogy:
Suppose you were a college student interning for the summer at Microsoft in Redmond, and you were packing clothes at home in Olympia. Now Seattle summers can be quite finicky — it could be blustery and rainy, or hot and sunny. It’s often hard to know what the weather will be like until the morning of. To that end, the prudent course of action would not be to pack only one set of clothes, but rather to pack clothes for either possibility. After all, it is far faster to change clothes from a suitcase than it is to drive home to Olympia every time the weather changes.
This is where the analogy starts to fall apart: what modern processors do to alleviate the time it takes to fetch data is not only fetch more data than they might need, but actually do calculations on that data ahead-of-time. This is known as speculative execution, and it is the heart of these vulnerabilities. To put this analogy in algorithmic form:
- Check the weather (execute multiple sub-processes that trigger sensors, relay data, etc.)
- If the weather is sunny, wear shorts-and-t-shirt
- Else wear jeans-and-sweatshirt
Remember, computers are stupid, but they are stupid fast: executing “wear shorts-and-t-shirt” or “wear jeans-and-sweatshirt” takes nanoseconds — what takes time is waiting for the weather observation. So to save time the processor will get you dressed before it knows the weather, usually based on history — what was the weather the last several days? That means you can decide on footwear, accessories, etc., all while waiting for the weather observation. That’s the other thing about processors: they can do a lot of things at the same time. To that end the fastest possible way to get something done is to guess what the final outcome will be and backtrack if necessary.
Meltdown
Now, imagine the algorithm was changed to the following:
- Check your manager’s calendar to see if they will be in the office
- If they will be in the office, wear slacks and collared-shirt
- If they will not be in the office, wear shorts-and-t-shirt
There’s just one problem: you’re not supposed to have access to your manager’s calendar. Keep in mind that computers are stupid: the processor doesn’t know this implicitly, it has to actually check if you have access. So in practice this algorithm is more like this:
- Check your manager’s calendar to see if they will be in the office
- Check if this intern has access to their manager’s calendar
- If the intern has access, access the calendar
- If they will be in the office, wear slacks and collared-shirt
- If they will not be in the office, wear shorts-and-t-shirt
- If the intern does not have access, stop getting dressed
- If the intern has access, access the calendar
- Check if this intern has access to their manager’s calendar
Remember, though, computers are very good at doing lots of things at once, and not very good at looking up data; in this case the processor will, under certain conditions, look at the manager’s calendar and decide what to wear before it knows whether or not it should look at the calendar. If it later realizes it shouldn’t have access to the calendar it will undo everything, but the clothes might end up slightly disheveled, which means you might be able to back out the answer you weren’t supposed to know.
I already said that the analogy was falling apart; it is now in complete tatters but this, in broad-strokes, is Meltdown: the processor will speculatively fetch and execute privileged data before it knows if it should or not; that process, though, leaves traces in cache, and those traces can be captured by a non-privileged user.
Explaining Spectre
Spectre is even more devious, but harder to pull off: remember, multiple users are using the same processor — roommates, if you will. Suppose I pack my suitcase the same as you, and then I “train” the processor to always expect sunny days (perhaps I run a simulation program and make every day sunny). The processor will start choosing shorts-and-t-shirt ahead of time. Then, when you wake up, the processor will have already chosen shorts-and-t-shirt; if it is actually rainy, it will put the shorts-and-t-shirt back, but ever-so-slightly disheveled.
This analogy has gone from tatters to total disintegration — it really doesn’t work here. Your data isn’t simply retrieved from main memory speculatively, it is momentarily parked in cache while the processor follows the wrong branch; it is quickly removed once the processor fixes it error, but I can still figure out what data was there — which means I’ve now stolen your data.
Meltdown is easier to explain because — Intel’s protestation to the contrary (Meltdown also affects Apple’s processors) — it is due to a design flaw. The processor is responsible for checking if data can be accessed, and to check too slowly, such that the data can be stolen, is a bug. That is also why Meltdown can be worked around in software (basically, there will be an extra step checking permissions before using the data, which is why the patch causes a performance hit).
Spectre is something else entirely: this is the processor acting as designed. Computers do basic calculations unfathomably quickly, but take forever to get the data to make those calculations: therefore doing calculations without waiting for bottlenecks, based on best guesses, is the best possible way to leverage this fundamental imbalance. Most of the time you will get results far more quickly, and if you guess wrong you are no slower than you would have been had you done everything in order.
This, too, is why Spectre affects all processors: the speed gains from leveraging modern processors’ parallelism and execution speed are so massive that speculative execution is an obvious choice; that the branch predictor might be trained by another user such that cache changes could be tracked simply didn’t occur to anyone until the last year (that we know of).
And, by extension, Spectre can’t be fixed by software: specific implementations can be blocked, but the vulnerability is built-in. New processors will need to be designed, but the billions of processors in use aren’t going anywhere. We’re going to have to muddle through.
Spectre and the State of Technology
I ended 2017 without my customary “State of Technology” post, and just as well: Spectre is a far better representation than anything I might have written. Faced with a fundamental imbalance (data fetch slowness versus execution speed), processor engineers devised an ingenious system optimized for performance, but having failed to envision the possibility of bad actors abusing the system, everyone was left vulnerable.
The analogy is obvious: faced with a fundamental imbalance (the difficulty of gaining and retaining users versus the ease of rapid iteration and optimization), Internet companies devised ingenious systems optimized for engagement, but having failed to envision the possibility of bad actors abusing the system, everyone was left vulnerable.
Spectre, though, helps illustrate why these issues are so vexing:
- I don’t believe anyone intended to create this vulnerability
- The vulnerability might be worth it — the gains from faster processors have been absolutely massive!
- Regardless, decisions made in the past are in the past: the best we can do is muddle through
So it is with the effects of Facebook, Google/YouTube, etc., and the Internet broadly. Power comes from giving people what they want — hardly a bad motivation! — and the benefits still may — probably? — outweigh the downsides. Regardless, our only choice is to move forward.
I wrote a follow-up to this article in this Daily Update.