Good morning,
No big preamble today — I apologize that this Update is out a bit late. This one took a bit of a rewrite.
On to the update:
Nvidia GTC
From Bloomberg:
Riding the surge of hype around ChatGPT and other artificial intelligence products, Nvidia Corp. introduced new chips, supercomputing services and a raft of high-profile partnerships Tuesday intended to showcase how its technology will fuel the next wave of AI breakthroughs. At the chipmaker’s annual developer conference on Tuesday, Chief Executive Officer Jensen Huang positioned Nvidia as the engine behind “the iPhone moment of AI,” as he’s taken to calling this inflection point in computing. Spurred by a boom in consumer and enterprise applications, such as advanced chatbots and eye-popping graphics generators, “generative AI will reinvent nearly every industry,” Huang said.
Nvidia, as is their wont, had a whole slew of releases — I counted 38 press releases in its Newsroom — and I wanted to start with one that didn’t merit a mention in the keynote. It’s titled AWS and NVIDIA Collaborate on Next-Generation Infrastructure for Training Large Machine Learning Models and Building Generative AI Applications:
Amazon Web Services, Inc. (AWS), an Amazon.com, Inc. company, and NVIDIA today announced a multi-part collaboration focused on building out the world’s most scalable, on-demand artificial intelligence (AI) infrastructure optimized for training increasingly complex large language models (LLMs) and developing generative AI applications.
The joint work features next-generation Amazon Elastic Compute Cloud (Amazon EC2) P5 instances powered by NVIDIA H100 Tensor Core GPUs and AWS’s state-of-the-art networking and scalability that will deliver up to 20 exaFLOPS of compute performance for building and training the largest deep learning models. P5 instances will be the first GPU-based instance to take advantage of AWS’s second-generation Elastic Fabric Adapter (EFA) networking, which provides 3,200 Gbps of low-latency, high bandwidth networking throughput, enabling customers to scale up to 20,000 H100 GPUs in EC2 UltraClusters for on-demand access to supercomputer-class performance for AI.
P5 instances are Nvidia’s DGX H100, which is basically 8 H100s packaged together such that they can be addressed as if it’s a single GPU. The reason I am starting here is that this is basically an evolution of Amazon’s P4 family of instances which are based on the A100. In other words, it’s the same model that Nvidia’s machine learning focused GPUs have long been available under. It’s up to the companies using these instances to leverage them, likely using Nvidia’s CUDA software, to train new models, run inference, etc. I would imagine AWS will also soon have instances that feature Nvidia’s H100 NVL, which is a version of the H100 that is specifically tuned for inference, which will be the preponderance of AI workloads going forward (inference is actually using the model; training is making it).
The H100 NVL was announced alongside a few other application specific versions of Nvidia’s offerings: the L4 is focused on video streaming, the L40 on graphics (including image and video generation), and Grace-Hopper on recommendation systems. This is how Huang introduced the products:
Deep learning has opened giant markets: automated driving, robotics, smart speakers, and reinvented how we shop, consume news, and enjoy music. That’s just the tip of the iceberg. AI is at an inflection point as generative AI has started a new wave of opportunities, driving a step function increase in inference workloads. AI can now generate diverse data, spanning voice, text, images, video, and 3D graphics, to proteins and chemicals. Designing a cloud data center to process generative AI is a great challenge. On the one hand, a single type of accelerator is ideal because it allows the data center to be elastic and handle the unpredictable peaks and valleys of traffic. On the other hand, no one accelerator can optimally process the diversity of algorithms, models, data types, and sizes. Nvidia’s one architecture platform offers both acceleration and elasticity. Today, we are announcing our new inference platform: four configurations, one architecture, one software stack.
Right there in that one paragraph is the aspect of Nvidia generally and Huang specifically that sometimes makes people roll their eyes: how is it that the company is seemingly on top of every single computing fad? What about actually focusing on something? In fact, though, this gets Nvidia backwards: the company does focus — specifically, the company focuses on one architecture, which is highly differentiated by software. I explained how this led to an endless number of new announcements back in 2021:
This is a useful way to think about Nvidia’s stack: writing shaders is like writing assembly, as in its really hard and very few people can do it well. CUDA abstracted that away into a universal API that was much more generalized and approachable — it’s the operating system in this analogy. Just like with operating systems, though, it is useful to have libraries that reduce duplicative work amongst programmers, freeing them to focus on their own programs. So it is with CUDA and all of those SDKs that Huang referenced: those are libraries that make it much simpler to implement programs that run on Nvidia GPUs.
This is how it is that a single keynote can cover “Robots and digital twins and games and machine learning accelerators and data-center-scale computing and cybersecurity and self-driving cars and computational biology and quantum computing and metaverse-building-tools and trillion-parameter AI models”; most of those are new or updated libraries on top of CUDA, and the more that Nvidia makes, the more they can make.
This isn’t the only part of the Nvidia stack: the company has also invested in networking and infrastructure, both on the hardware and software level, that allows applications to scale across an entire data center, running on top of thousands of chips. This too requires a distinct software plane, which reinforces that the most important thing to understand about Nvidia is that it is not a hardware company, and not a software company: it is a company that integrates both.

The most interesting part of this keynote was about that last paragraph, specifically that “distinct software plane.” AWS instances are accessed via the AWS software plane; now Nvidia is making their own software plane into its own cloud service.
DGX Cloud
From the keynote:
We are at the iPhone moment of AI. Startups are racing to build disruptive products and business models, while incumbents are looking to respond. Generative AI has triggered a sense of urgency in enterprises worldwide to develop AI strategies. Customers need to access Nvidia AI easier and faster.
We are announcing Nvidia DGX Cloud, through partnerships with Microsoft Azure, Google GCP, and Oracle OCI to bring Nvidia DGX supercomputers to every company instantly from a browser. DGX Cloud is optimized to run Nvidia AI Enterprise, the world’s leading acceleration library suite, for end-to-end development and deployment of AI. DGX Cloud offers customers the best of Nvidia AI, and the best of the world’s leading cloud service providers. This partnership brings the Nvidia ecosystem to the CSPs, while amplifying Nvidia’s scale and reach. This win-win partnership gives customers racing to engage generative AI instant access to Nvidia and global scale clouds. We are excited by the speed, scale, and reach of this cloud extension of our business model.
In short, Nvidia is expanding its stack upwards:
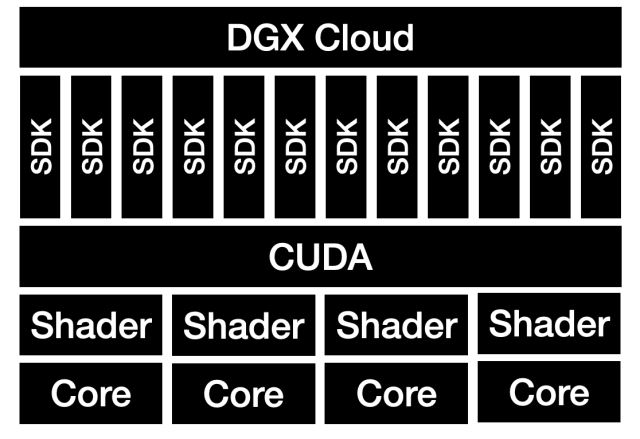
There’s just one problem, though: AWS certainly does not have the greatest interface in the world, but that’s not a sufficient reason to choose the Nvidia alternative. What businesses want is not just access to the GPUs undergirding generative AI models: they want models of their own — and that’s precisely how Nvidia plans to differentiate their offering.
Generative AI will reinvent nearly every industry. Many companies can use the excellent generative AI’s coming to market. Some companies need to build custom models with their proprietary data that are experts in their domain. They need to set up usage guardrails and refine their models to align with their company’s safety, privacy, and security requirements. The industry needs a foundry — a TSMC for custom large language models.
Today we announced the Nvidia AI Foundations, a cloud service for customers needing to build, refine, and operate custom large language models and generative AI, trained with their proprietary data and for their domain-specific tasks. Nvidia AI Foundations comprise language, visual, and biology model-making services. Nvidia Nemo is for building custom language text-to-text generative models. Customers can bring their model, or start with the Nemo pre-trained language models, ranging from GPT 8, GPT 43, and GPT 530 billion parameters. Throughout the entire process Nvidia AI experts will work with you, from creating your proprietary model, to operations.
Here’s the kicker: Nemo and Picasso (the image generation model) only run on DGX Cloud:

Stepping back, I suspect that Nvidia sees both an opportunity and a threat. The opportunity is that all kinds of businesses want to incorporate generative AI, and they have no idea where to start. Nvidia is providing exactly that, and is doing so to a group of potential customers — enterprise — that is famous for getting itself locked in to whatever platform it standardizes on first.
The threat, meanwhile, is that the old AWS model depends on Nvidia maintaining a software edge with CUDA that everyone in the industry is trying to get away from. Cloud vendors would love to be able to offer AMD alternatives, or even better, their own custom built chips for training and inference (or use them for their own needs). CUDA is, to be sure, still a meaningful differentiator, with a big ecosystem, but if the primary goal is simply training and running inference on large language models then both the possibility and attraction of getting out from under Nvidia is larger than ever.
To put it another way, it used to be that the majority of innovation was happening in terms of different applications of machine learning; Nvidia provided CUDA to make that innovation happen. Now, though, the preponderance of new use cases and companies will be on top of large language models, and Nvidia doesn’t want to get stuck at the level of implementation details.
Nvidia’s Partners
One more bit from the DGX Cloud introduction:
Oracle Cloud Infrastructure — OCI — will be the first Nvidia DGX Cloud. OCI has excellent performance. They have a two-tier computing fabric and management network. Nvidia CX7, with the industry’s best RDMA, is the computing fabric, and Bluefield 3 will be the infrastructure processor for the management network. The combination is a state-of-the-art DGX AI supercomputer that can be offered as a multi-tenant cloud service.
I think the fact that Oracle is leading the way here speaks to why cloud service providers would want to support Nvidia in this effort. After all, why is anyone choosing Oracle as their cloud service? Now, though, they aren’t choosing Oracle: they’re choosing Nvidia, and Oracle is along for the ride, more than willing to implement the full Nvidia stack and perhaps, for that reason, be Nvidia’s preferred provider.
DGX Cloud, meanwhile, is targeting Microsoft’s core customer base; it makes sense that Microsoft would want to play ball to keep those customers on Azure, even if it’s lower margin. I’m a little more stumped by Google: I guess they also have an enterprise business to preserve, and maybe they are looking for growth wherever they can find it.
The one company that is missing is AWS. AWS is already the leader in the space, and likely the most reticent to run the risk of Nvidia abstracting them away. AWS has also invested heavily in its own management and networking infrastructure, and may not be fully compatible with Nvidia’s approach. What will be interesting to watch is if, as long as those H100s are in short supply, AWS seems to always take longer to get theirs.
The broader takeaway is that Huang’s declaration that generative AI was a paradigm shift like the PC, the Internet, mobile, etc. was not just talk: DGX Cloud is a substantial shift by Nvidia in the value chain, and it’s one that makes sense if you believe that the there is a much larger opportunity to capture on top of large language models than underneath them.
This Update will be available as a podcast later today. To receive it in your podcast player, visit Stratechery.
The Stratechery Update is intended for a single recipient, but occasional forwarding is totally fine! If you would like to order multiple subscriptions for your team with a group discount (minimum 5), please contact me directly.
Thanks for being a subscriber, and have a great day!