
Jimmy Iovine spared no words when it came to his opinion of algorithms during the unveiling of Apple Music:
The only song that matters as much as the song you’re listening to right now is the one that follows this. Picture this: you’re in a special moment…and the next song comes on…BZZZZZ Buzzkill! It probably happened because it was programmed by an algorithm alone. Algorithms alone can’t do that emotional task. You need a human touch. And that’s why at Apple Music we’re going to give you the right song [and] the right playlist at the right moment all on demand.
About Beats 1, the new Apple Music radio station, Iovine added:
[It] plays music not based on research, not based on genre, not based on drum beats, only music that is great and feels great. A station that only has one master: music itself.
According to the Apple Music website “Zane Lowe and his handpicked team of renowned DJs create an eclectic mix of the latest and best in music”; then again, if you keep scrolling the page, you’re reminded there is more to Beats 1 than curated music:
Building your own station couldn’t be easier. Just select any song, album, or artist and it will practically build itself. Adjust the mix to hear more songs you know or discover unfamiliar gems. Love a track? We’ll play more like it. The more you fine-tune the station, the more personalized it becomes.
That sounds a bit like an algorithm. So which is more important, and why?
The Rise of Curation
Curation has been all over the news for the past few weeks. At that same keynote Apple introduced Apple News, and while the presentation made it sound a bit like those user-generated radio stations — Craig Federighi introduced it as “Beautiful content from the world’s greatest sources personalized for you” — it turns out that Apple is hiring editors to, in the words of the Apple job posting, “Ensur[e] that important breaking news stories are surfaced quickly, and enterprise journalism is rewarded with high visibility.”
Apple News is hardly the only effort in the space: a month previously the New York Times released version 2 of its NYT Now app; the big headline was that the app was now free, but just as interesting was the decision to decrease the number of articles from the New York Times itself and intersperse them with a nearly equal number of articles from other publications with the intent of providing a one-stop curated news experience.1 BuzzFeed just released their own take on the concept with the BuzzFeed News app which adds tweets to a mix of BuzzFeed content and content from around the web, all helpfully summarized in easily digestible bullet points.
Twitter itself announced plans to get in on the game with its forthcoming Project Lightning, a tool that, according to BuzzFeed, “will bring event-based curated content to the Twitter platform.” The articles notes:
Launch one of these events and you’ll see a visually driven, curated collection of tweets. A team of editors, working under Katie Jacobs Stanton, who runs Twitter’s global media operations, will select what it thinks are the best and most relevant tweets and package them into a collection…They’ll use data tools to comb through events and understand emerging trends, and pluck the best content from the ocean of updates flowing across Twitter’s servers. But human beings will decide which tweets to include.
Lightning hasn’t launched, but Snapchat’s Live Stories have been drawing in huge viewer numbers for some time now; they too are driven by curation: Recode reports that “the company has grown its team of Live Story curators from fewer than 10 people to more than 40 people” since January, and is now producing multiple events per day. Even Instagram is adding curation to its new Explore page.
When Curating Makes Sense
There are two important advantages to curation:
- First, where context is critical to immediately determining how important something is — as is the case with news — human curators are, at least for now, superior to algorithms. Humans are also able to quickly identify that these forty stories are about the same event, and have the taste to decide which is the best option to present
- Taste figures much more prominently when it comes to Apple Music and other similar endeavors. The DJ-focused Beats 1 “radio” station, for example, is clearly intended to make certain songs popular, not simply identify popularity after it is already attained. This in particular is a natural fit for Apple, and is the part of Apple Music I am most intrigued by: the company is most comfortable setting trends, not following them (as is the case with the core streaming service)
It’s possible that algorithms will one day be superior to humans at both of these functions, but I’m skeptical: the critical recognition of context and creativity are the two arenas where computers consistently underperform humans.
The Algorithmic Giants
That said, despite curation’s advantages the two biggest content players of all — Google and Facebook — are pure algorithmic plays. Google News has always been algorithmically driven, but the more important tool for content is Google search itself, which uses the most valuable algorithm in the world to not only find content but to rank it as well. Facebook, meanwhile, is in some respects the exact opposite of Google: rather than responding to an input Facebook proactively selects what you see when you open the app; that selection, though, is also 100% algorithmically driven.

When considering the question of what is better, algorithms or curation, I think this observation that the core Facebook and Google algorithms are actually solving two very different problems is a useful one. Google is seeking the single best answer to a direct query from an effectively infinite number of data points (i.e. the Internet); while the answer it gives is to a degree influenced by the profile Google has built about you, or the various contextual clues surrounding your search, for most queries there is one right answer that Google will return to anyone who searches for the term in question. In short, the data set is infinite (which means no human is capable of doing the job), but the target is finite.
Facebook, on the other hand, creates a unique news feed for all of its 1.44 billion users: while Facebook has a huge amount of data,2 the amount of information any one user will ever be interested in is finite; what is infinite are the number of targets (which means Facebook could never employ enough humans to do the job). In other words, neither Google nor Facebook are able to rely on curation even if they wanted to, but the reasons that Google and Facebook rely on algorithms differs:

However, as I just noted, these two reasons run in the opposite direction: Google does personalize a bit, but it mostly concerned with one right answer, while any single Facebook user doesn’t care and will never care about the vast majority of Facebook’s data. Presuming this relationship holds, you can actually put the above two graphs together:

This curve is a useful way to think about the aforementioned curation initiatives: curation works best when there is a good amount of data, but not too much, and the goal is a fair bit of personalization, but not on an individual basis.
Curating News
The Curation-Algorithm curve makes it clear why news is an obvious curation candidate: while a lot of news happens everywhere all the time, it’s still a lot less than the sum total of information on the Internet. Moreover, the sort of news most people care about tends to be relatively widely applicable, which means personalization is useful but only to a degree. In other words, news mostly sits at the bottom of this curve.
Newspapers figured this out a long time ago: editors were curators, deciding what went on the front page, what was on page 13, and what was buried completely. It mostly worked, although many editors perhaps became too enamored with “prestige” stories like world news as opposed to truly understanding what readers wanted. Moreover, once the Internet destroyed geographic monopolies, it quickly became apparent that most newspapers didn’t have the best content on the particular stories they covered; readers fled to superior alternatives wherever they happened to find them and curation gave way to social services like Twitter and Facebook.
This is what makes the NYT Now and BuzzFeed News apps so interesting: both accept the idea that their respective publications don’t have a monopoly on the best content, even as both are predicated on the idea that curation remains valuable. Apple News takes this concept further by being completely publication agnostic.
The Twitter Question
The current Twitter product, based on a self-curated time-line, doesn’t really fit well on the Curation-Algorithm curve. Power users, through the long and arduous process of following and unfollowing a huge number of people, can ultimately arrive at a highly personalized feed that is relevant to their interests. Beginners, though, are presented with a feed that is nominally about their interests as decided by a torturous first-run experience but which in reality is a stream of mumbo-jumbo.
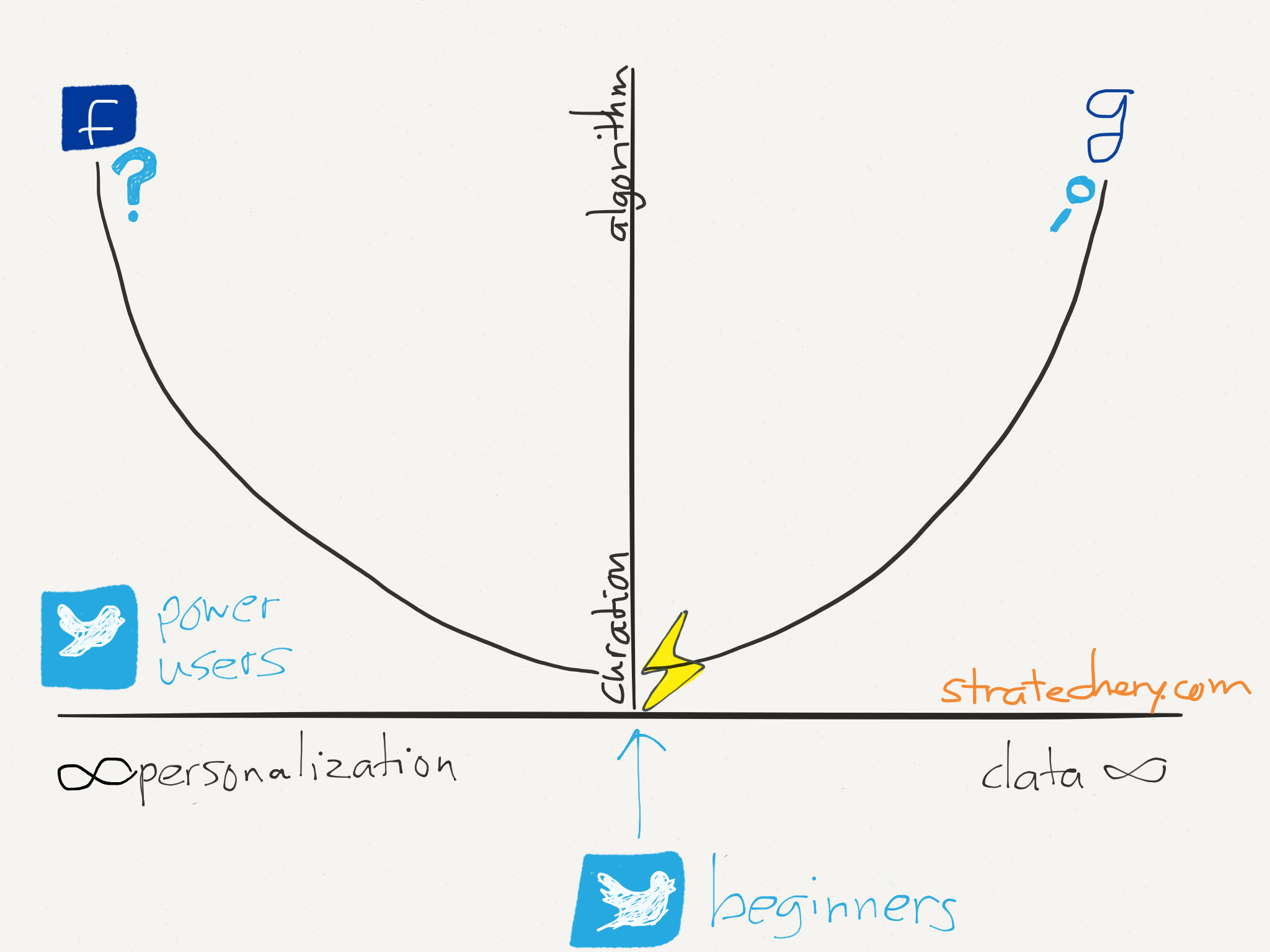
Project Lightning is clearly focused on hitting the algorithmic sweet spot with event-based “channels”: it’s an obvious move that should have been done years ago. What is perhaps more interesting, though, is whether Twitter ought to pursue an algorithmic feed: I think the answer is “Yes”. While Twitter’s value is its interest graph, its organizing principle to date has been people; an algorithmic feed would help Twitter more effectively bridge that disconnect.3
Curating Ethics
There is one more big reason why tech companies have previously given curation short shrift, and it’s the flipside of Apple’s efforts with Music: it is a lot easier to abscond with responsibility for what you display if you can blame it on an algorithm. Human curation, on the other hand, makes it explicitly clear who is responsible for what is seen by the curating company’s users.
The potential quandaries are easy to imagine: will Apple’s News app highlight a story about worker conditions in China?4 Will Snapchat’s planned coverage of the 2016 election favor one candidate over the other? Would Twitter have created an “event” around the exit of its CEO?
On the other hand, hiding behind algorithms is increasingly untenable as well. For one, algorithms are made by humans; choosing which story appears in your Facebook feed is the responsibility of Facebook whether they choose it explicitly or implicitly via an algorithm. Google, for its part, has successfully argued that its algorithm is protected free speech, an admission of ultimate responsibility even more profound than the company’s regular algorithmic updates explicitly designed to adjust rankings.
Google in particular has a special responsibility. I wrote in Economic Power in the Age of Abundance:
The Internet is a world of abundance, and there is a new power that matters: the ability to make sense of that abundance, to index it, to find needles in the proverbial haystack. And that power is held by Google. Thus, while the audiences advertisers crave are now hopelessly fractured amongst an effectively infinite number of publishers, the readers they seek to reach by necessity start at the same place – Google – and thus, that is where the advertising money has gone.
Google’s position as the Internet chokepoint has been exceptionally profitable, but with great power comes great responsibility: in a welcome development Google is slowly accepting said responsibility and delisting revenge porn upon request. It’s the right move for both moral and practical reasons — moral because Google is uniquely positioned to prevent people’s lives from being ruined, and practical because if Google didn’t take action eventually the government would compel them. Indeed, that has already happened in Europe with the “right to be forgotten”, and while there is certainly a debate to be had as to whether or not that is good policy, the idea that Google is a hapless bystander is no longer viable.
Ultimately, I see the embrace of curation as a mark of maturation of the technology industry. Today’s technology companies have massive amounts of influence over what people the world over see and consume, and while there is a long ways to go when it comes to transparency about what is seen and why, at least everyone is now being honest about possessing that power in the first place.
Moreover, I’m excited about the real user benefit that can come from balancing algorithms and curation: while Facebook and Google rightly focus on algorithms only, most content is best delivered by a mixture; getting that mixture right will likely prove to be both massively popular and massively valuable.
Discuss this Article on the Stratechery Forum (members-only)
The previous NYT Now app included articles from other publications as well, but in a different tab ↩
The vast majority of which is inaccessible to Google, to the latter’s consternation ↩
One more thing: don’t sleep on Twitter search. It remains the single best way to quickly catch up on anything that happened in the last few hours ↩
For the record, I do believe Apple’s record is better than most ↩