
Everyone knows the story of how IBM gave away the castle to Microsoft (and Intel): besieged by customers demanding low-powered personal computers, the vertically-integrated mainframe-centric company tasked a team in Boca Raton, Florida, far from the company’s headquarters in Armonk, New York, to create something quickly to appease these low-margin requests. Focused on speed and cost said team decided to outsource nearly everything, including the operating system and processor. The approach paid off, at least when it came to IBM’s goals: while IBM’s integrated products normally took half a decade to develop and launch, the Boca Raton team moved from concept to shipping product in only 12 months. However, the focus on standard parts meant that all of the subsequent value in the PC, which massively exceeded the mainframe business, went to the two exclusive suppliers: Microsoft and Intel.1
Fewer are aware that the PC wasn’t IBM’s only internal-politics-driven value giveaway; one of the most important software applications on those mainframes was IBM’s Information Management System (IMS). This was a hierarchical database, and let me pause for a necessary caveat: for those that don’t understand databases, I’ll try to simplify the following explanation as much as possible, and for those that do, I’m sorry for bastardizing this overview!
Database Types
A hierarchical database is, well, a hierarchy of data:
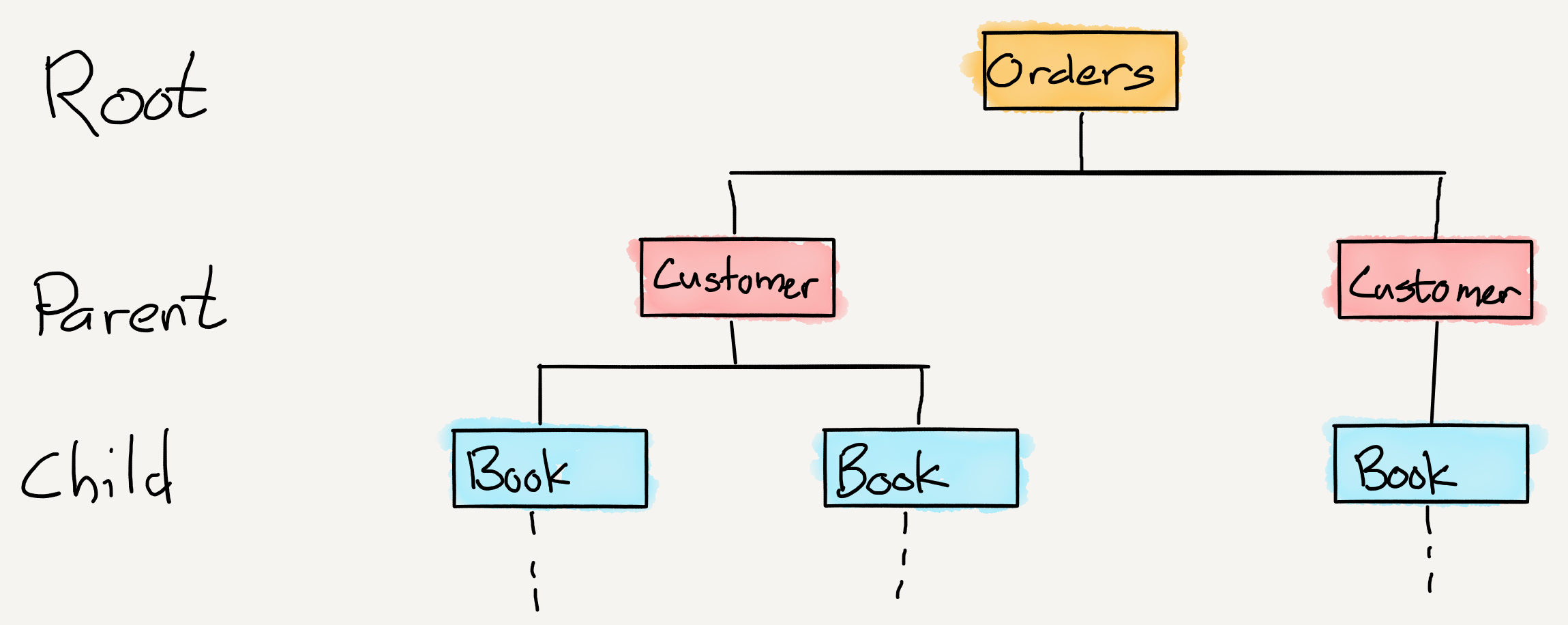
Any particular piece of data in a hierarchical database can be found by either of two methods: either know the parent and find its children, or know the children and find its parent. This is the easiest sort of database to understand, and, at least for early computers, it was the easiest to implement: define the structure, enter data, and find that data layer by traversing the hierarchy until you find the relevant parent or child. Or, more realistically, leverage your knowledge of the hierarchy to go to a specific spot.
However, there were two big limitations with hierarchical databases: first, relationships were pre-determined; what was a parent and what was a child were decisions made before any data was actually entered. This made it extremely difficult to alter a database once it was in use. Secondly, queries analyzing the children of different parents are impractical: you would need to traverse the hierarchy to retrieve information for every potential item before discarding the vast majority to get the data set you wish to analyze.
In 1969, an IBM computer scientist named Edgar F. Codd wrote a seminal paper called A Relational Model of Data for Large Shared Data Banks that proposed a new approach. The introduction is remarkably lucid, even for laypeople:
Future users of large data banks must be protected from having to know how the data is organized in the machine (the internal representation). A prompting service which supplies such information is not a satisfactory solution. Activities of users at terminals and most application programs should remain unaffected when the internal representation of data is changed and even when some aspects of the external representation are changed. Changes in data representation will often be needed as a result of changes in query, update, and report traffic and natural growth in the types of stored information.
This paper was the foundation of what became known as relational databases: instead of storing data in a hierarchy, where the relationship between said data defines its location in the database, relational databases contain tables; every piece of data is thus defined by its table name, column name, and key value, not by the data itself (which is stored elsewhere). That by extension means that you can understand data according to its relationship to all of the other data in the database; a table name could also be a column name, just as a key value could also be a table name.
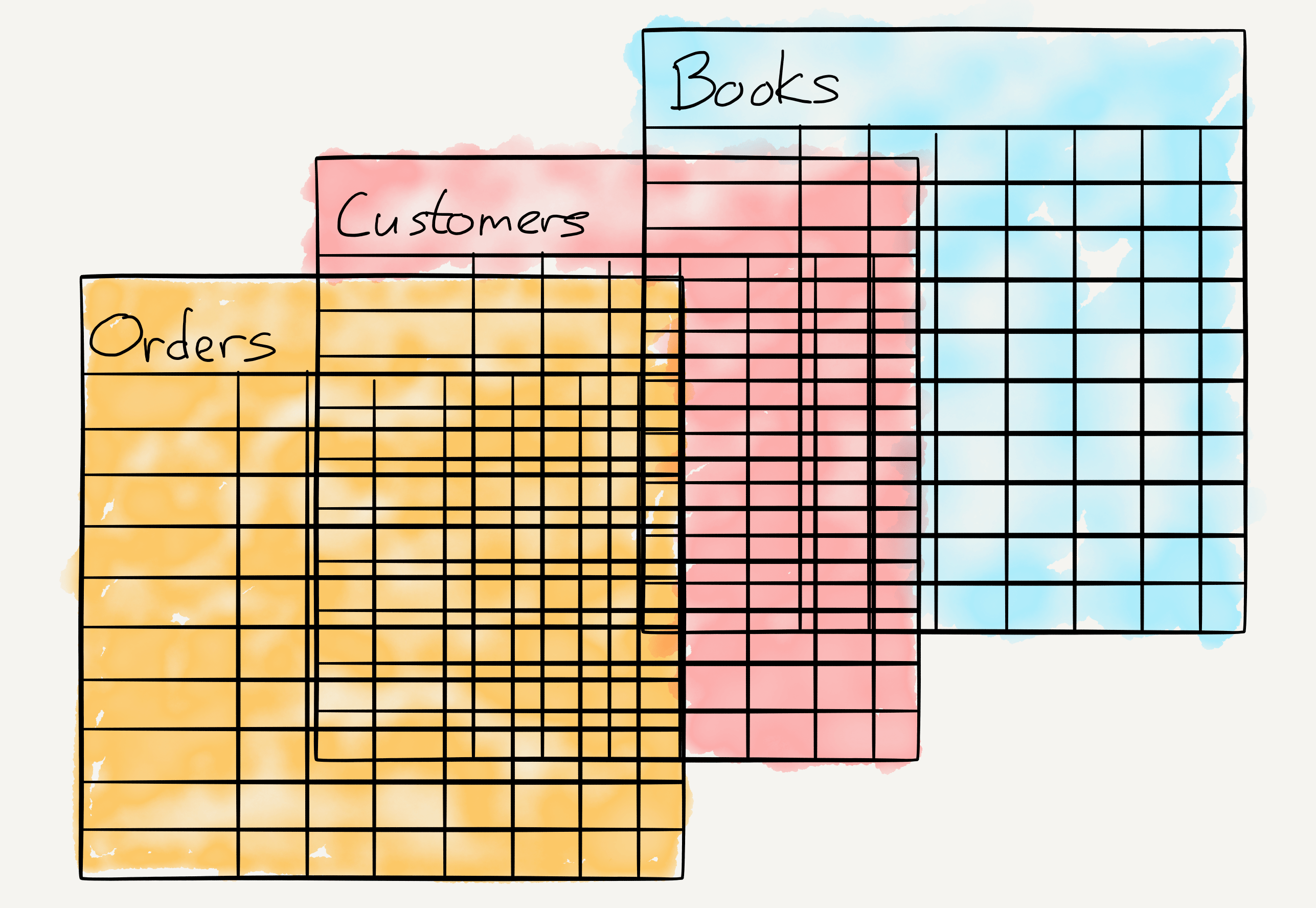
This approach had several huge benefits: first, databases could be expanded with new data categories without any impact on previous data, or needing to completely rewrite the hierarchy; just add new tables. Two, databases could scale to accommodate arbitrary amounts and types of data because the data wasn’t actually in the database; remember it was abstracted away in favor of integers and strings of text. Third, using a “structured query language” (SQL) you could easily generate reports on those relationships (What were the 10 most popular books ordered by customers over 40?), and because said queries were simply examining the relationship between integers and strings you could ask almost anything. After all, figuring out the relationship between locations in the database is no longer scanning a tree — which is inherently slow and mostly blind, if you don’t know what you’re looking for — but is math. Granted, it was very hard math — many at the time thought it was too hard — but the reality of Moore’s Law was slowly being realized; it wouldn’t be hard math forever.
Phew. I’d imagine that was as painful to read as it was to write, but this is the takeaway: hierarchical databases are limited in both capability and scalability by virtue of being pre-defined; relational databases are far more useful and scalable by virtue of abstracting away the data in favor of easily computable values.
Oracle’s Rise
Dr. Codd’s groundbreaking idea was almost completely ignored by IBM for several years in part because of the aforementioned IMS; Codd was basically saying that one of IBM’s biggest moneymakers was obsolete for many potential database applications, and that was a message IBM’s management was not particularly interested in hearing. In fact, even when IBM finally did build the first-ever relational database in 1977 (it was called System R and included a new query language called SQL),2 they didn’t release it commercially; only in 1982 did the company release its first relational database software called SQL/DS. Naturally it only ran on IBM mainframes, albeit small ones; IMS ran on the big iron.
Meanwhile, a young programmer named Larry Ellison had formed a company called Software Development Laboratories, originally to do contract work, but quickly decided that selling packaged software was a far better proposition: doing the work once and reselling it multiple times was an excellent way to get rich. They just needed a product, and IBM effectively gave it to them; because the System R team was being treated as a research project, not a commercial venture, they happily wrote multiple papers explaining how System R worked, and published the SQL spec. Software Development Laboratories implemented it and called it Oracle, and in 1979 sold it to the CIA; a condition of the contract was that it run on IBM mainframes.3
In other words, IBM not only created the conditions for the richest packaged software company ever to emerge (Microsoft), they basically gave an instruction manual to the second.
The Packaged Software Business
The packaged software industry was a bit of a hybrid between the traditional businesses of the past and the pure digital businesses of the Internet era (after all, there was no Internet). On the one hand, as Ellison quickly realized, software had zero marginal costs: once you had written a particular program, you could make an infinite number of copies. On the other hand, distribution was as much a challenge as ever; in the case of Oracle’s relational database, Relational Software Inc. (née Software Development Laboratories; the company would name itself “Oracle Systems Corporation” in 1982, and then today’s Oracle Corporation in 1995) had to build a sales force to get their product into businesses that could use it (and then ship the actual product on tape).
The most economical way to do that was to build the sort of product that was mostly what most customers wanted, and then work with them to get it actually working. Part of the effort was on the front-end — Oracle was quickly rewritten in the then-new programming language C, which had compilers for most platforms, allowing the company to pitch portability — but even more came after the sale: the customer had to get Oracle installed, get it working, import their data, and only then, months or years after the original agreement, would they start to see a return.
Eventually this became the business model: Oracle’s customers didn’t just buy software, they engaged in a multi-year relationship with the company, complete with licensing, support contracts, and audits to ensure Oracle was getting their just dues. And while customers grumbled, they certainly weren’t going anywhere: those relational databases and the data in them were what made those companies what they were; they’d already put in the work to get them up-and-running, and who wanted to go through that again with another company? Indeed, given that they were already running Oracle databases and had that existing relationship, it was often easier to turn to Oracle for the applications that ran on top of those databases. And so, over the following three decades, Oracle leveraged their initial advantage to an ever-increasing share of their customers’ IT spend. Better the devil you know!
Amazon’s Optionality
The proposition behind Amazon Web Services (AWS) could not be more different: companies don’t make up-front commitments or engage in years-long integration projects. Rather, you sign-up online, and you’re off. To be fair, this is an oversimplification when it comes to Amazon’s biggest customers, who negotiate prices and make long-term commitments, but that’s a recent development; AWS’ core constituency has always been startups taking advantage of server infrastructure that used to cost millions of dollars to build minimum viable products where all of their costs are variable: use AWS more (because you’re gaining customers), pay more; use it hardly at all, because you can’t find product-market fit, and you’re out little more than the opportunity cost of not doing something else.
It’s the option value that makes AWS so valuable: need more capacity? Just press a button. Need to build a new feature? AWS likely has a pre-built service for you to incorporate. Sure, it can get expensive — a common myth is that AWS is winning on price, but actually Amazon is among the more expensive options — but how much is it worth to have exactly what you need when you need it?
Ellison, meanwhile, got up on stage at the company OpenWorld conference this week and declared that “Amazon’s lead is over” when it comes to Infrastructure-as-a-Service, all because Oracle’s top-of-the-line server instance was faster and cheaper than Amazon. Well sure, but hierarchical databases were faster than relational databases too; speed isn’t everything, nor is price. Optionality and scalability matter just as much as they always have, and in this case Oracle’s quite basic offering isn’t remotely competitive.
Ellison’s statement is even more ridiculous when you look at the number that really matters when it comes to cloud services: capital expenditures. Over the last twelve months Oracle has totaled $1.04 billion in capital expenditures; Amazon spent $3.36 billion in the last quarter,4 and $10.9 billion in the last twelve months.5 Infrastructure-as-a-Service is not something you build-to-order; it’s the fact that the infrastructure and all the attendant services that rest on top of that infrastructure are already built that makes AWS’s offering so alluring. Oracle is not only not catching up, they are falling further behind.
SaaS Focus
In his keynote Ellison argued that infrastructure spending wasn’t necessarily the place to gauge Oracle’s cloud commitment; instead he pointed out that the company has spent a decade moving its various applications to the cloud. Indeed, the company spent a significant 17% of revenues last quarter on research-and-development, and Ellison bragged that Oracle now had 30+ SaaS applications and that the sheer number mattered:
What is Oracle’s strategy: what do we think customers want, what do we do in in SaaS? It’s the same thing: if we can figure out what customers want and deliver that customers are going to pick our stuff and buy our stuff. And we think what they want is complete and integrated suites of products, not one-off products. Customers don’t want to have to integrate fifty different products from fifty different vendors. It’s just too hard. It’s simply too hard and the associated security risks and labor costs and reliability problems is just too much. So our big focus is not delivering one, two, three, four applications, but delivering complete suites of applications, for ERP, for human capital management, for customer relationship management, sometimes called customer experience, or CX. That’s our strategy in SaaS: complete and integrated suites.
What Ellison is arguing was absolutely correct when it came to on-premise software; I wrote about exactly this dynamic with regards to Microsoft in 2015:
Consider your typical Chief Information Officer in the pre-Cloud era: for various reasons she has bought in to some aspect of the Microsoft stack (likely Exchange). So, in order to support Exchange, the CIO must obviously buy Windows Server. And Windows Server includes Active Directory, so obviously that will be the identity service. However, now that the CIO has parts of the Microsoft stack in place, she is likely to be much more inclined to go with other Microsoft products as well, whether that be SQL Server, Dynamics CRM, SharePoint, etc. True, the Microsoft product may not always be the best in a vacuum, but no CIO operates in a vacuum: maintenance and service costs are a huge concern, and there is a lot to be gained by buying from fewer vendors rather than more. In fact, much of Microsoft’s growth over the last 15 years can be traced to Ballmer’s cleverness in exploiting this advantage through both new products and also new pricing and licensing agreements that heavily incentivized Microsoft customers to buy ever more from the company.
As noted above, this was the exact same strategy as Oracle. However, enterprise IT decision-making is undergoing dramatic changes: first, without the need for significant up-front investment, there is much less risk in working with another vendor, particularly since trials usually happen at the team or department level. Second, without ongoing support and maintenance costs there is much less of a variable cost argument for going with one vendor as well. True, that leaves the potential hassle of incorporating those fifty different vendors Ellison warned about, but it also means that things like the actual quality of the software and the user experience figure much more prominently in the decision-making — and the point about team-based decision-making makes this even more important, because the buyer is also the user.
Oracle in the Middle
In short, what Ellison was selling as the new Oracle looks an awful lot like the old Oracle: a bunch of products that are mostly what most customers want, at least in theory, but with neither the flexibility and scalability of AWS’ infrastructure on one side nor the focus and commitment to the user experience of dedicated SaaS providers on the other. To put it in database terms, like a hierarchical database Oracle is pre-deciding what its customers want and need with no flexibility. Meanwhile, AWS and dedicated SaaS providers are the relational databases, offering enterprises optionality and scalability to build exactly what they need for their business when they need it; sure, it may not all be working yet, but the long-term trends couldn’t be more obvious.
It should be noted that much of this analysis primarily concerns new companies that are building out their IT systems for the first time; Oracle’s lock on its existing customers, including the vast majority of the largest companies and governments in the world, remains very strong. And to that end its strategy of basically replicating its on-premise business in the cloud (or even moving its cloud hardware on-premise) makes total sense; it’s the same sort of hybrid strategy that Microsoft is banking on. Give their similarly old-fashioned customers the benefit of reducing their capital expenditures (increasing their return on invested capital) and hopefully buy enough time to adapt to a new world where users actually matter and flexible and focused clouds are the best way to serve them.
IBM did force Intel to share its design with AMD to ensure dual suppliers ↩
Amazingly, IBM kept Codd separate from the engineering team ↩
To be fair to IBM, SQL/DS and their later mainframe product, DB2, were far more reliable than Oracle’s earliest versions ↩
Specifically, Amazon spent $1.7 billion in capital expenditures and $1.7 billion in capital lease commitments ↩
This expenditure includes distribution centers for the retail business; however, no matter how your split it, Amazon is spending a lot more ↩