This Article is available as a video essay on YouTube
Om Malik has been observing, writing about, and investing in technology for going on three decades; that’s one reason I find his unabashed enthusiasm for the Apple Vision Pro to be notable. Malik wrote on his blog:
Apple touts Vision Pro as a new canvas for productivity and a new way to play games. Maybe, maybe not. Just as the Apple Watch is primarily a health-related device that also does other things, including phone calls, text messages, and making payments. Similarly, the primary function for Vision Pro is ‘media’ — especially how we consume it on the go. Give it a few weeks, and more people will come to the same conclusion.
In 2019, I wrote an essay about the future of television (screen):
With that caveat, I think both, the big (TV) and biggest (movie theater) screens are going to go the way of the DVD. We could replace those with a singular, more personal screen — that will sit on our face. Yes, virtual reality headsets are essentially the television and theaters of the future. They aren’t good enough just yet — but can get better in the years to come as technologies to make the headsets improve.
Apple has made that headset. Apple Vision Pro has ultra-high-resolution displays that deliver more pixels than a 4K TV for each eye. This gives you a screen that feels 100 feet wide with support for HDR content. The audio experience is just spectacular. In time, Apple’s marketing machine will push the simple message — for $3,500, you get a full-blown replacement for a reference-quality home theater, which would typically cost ten times as much and require you to live in a McMansion.
Malik expounded on this point last week in a Stratechery Interview:
But the thing is you actually have to be mobile-native to actually appreciate something like this. So if you’ve grown up watching a 75-inch screen television, you probably would not really appreciate it as much. But if you are like me who’s been watching iPad for ten-plus years as my main video consumption device, this is the obvious next step. If you live in Asia, like you live in Taiwan, people don’t have big homes, they don’t have 85-inch screen televisions. Plus, you have six, seven, eight people living in the same house, they don’t get screen time to watch things so they watch everything on their phone. I think you see that behavior and you see this is going to be the iPod.
The iPod was a truly personal device, which was not only what people wanted, but also a great business: why sell one stereo to a household when you can sell an iPod to every individual? You can imagine Apple feeling the same about the long-term trajectory of the Vision Pro: why sell a TV that sits on the wall of the living room when you can sell every individual a TV of their own? You can be sure that Apple isn’t just marketing this device to people who live alone: the EyeSight feature only makes sense if you are wearing the Vision Pro around other people.
I already commented about the dystopian nature of this vision when the Vision Pro was announced; for now I’m interested in the business aspects of this vision, and the iPod is a good place to start.
The iPod and the Music Labels
The iPod story actually starts with the Mac, and Apple’s vision of a “Digital Hub.” The company released iMovie in 1999, iDVD and iTunes two years later, and iPhoto a year after that. The release order is interesting: Apple thought that home movies would be the big new market for PCs, but the emergence of Napster in 1999 made it clear that music was a much more interesting market (digital cameras, meanwhile, were only just becoming a thing). That laid the groundwork for the iPod, which was released in the fall of 2001. I documented this history in Apple and the Oak Tree and noted:
One of my favorite artifacts from the brief period between the introduction of iTunes and the release of the iPod was Apple’s “Rip. Mix. Burn.” advertising campaign.
What is particularly amazing (that is, beyond the cringe-inducing television ad) is that Apple was arguably encouraging illegal behavior: it was likely legal to rip and probably legal to burn, presuming the CD that you made was for your own personal use. It certainly was not legal to share.

The iPod was predicated on the reality of file-sharing as well:
And yet, as much as “Rip. Mix. Burn.” may have walked the line of legality, the reality of iTunes — and the iPod that followed — was well on the other side of that line. Apple knew better than anyone that the iPod’s tagline — 1,000 songs in your pocket — was predicated on users having 1,000 digital songs, not via the laborious procedure of ripping legally purchased CDs, but rather via Napster and its progeny. By the spring of 2003 Apple had introduced the iTunes Music Store, a seamless and legal way to download DRM-protected digital music, but particularly in those early days the value of the iTunes Music Store to Apple was not so much that it was a selling point to consumers, but rather a means by which Apple could play dumb about how it was that its burgeoning number of iPod customers came to fill up their music libraries.
That description of the iTunes Music Store is perhaps a touch cynical, but it is impossible to ignore the importance of music piracy in Apple’s original deal with the record labels. Apple was able to make a deal in part because it was offering the carrot of increased digital revenue, but it was certainly aided by the stick of piracy obliterating CD sales.

Over the next few years the record labels would become increasingly resentful of Apple’s position in the market, but they certainly weren’t going anywhere; by 2008 iTunes was their biggest source of revenue, and it’s all but impossible for an ongoing business to give up revenue just because they think the arrangement under which they make that revenue is unfair.
The App Store
The iTunes Music Store does still exist, although its revenue contribution to the labels has long been eclipsed by streaming. It’s more important contribution to modern computing is that it provided the foundation for the App Store.
The App Store didn’t exist when Apple launched its iPhone in 2007; Apple provided a suite of apps that made the iPhone more capable than anything else on the market, and assumed the web would take care of the rest. Developers, though, wanted to build apps; in September 2007 Iconfactory released Twitterific, a Twitter client that ran on jail-broken iPhone devices, and more apps followed. The following year Apple gave its eager developers what they wanted: an officially supported SDK and an App Store to distribute their apps, for free or for pay; in the case of the latter Apple would, just as it did with songs, keep 30% of the purchase price (and cover processing fees).
This period of the App Store didn’t require any sticks: the capability of the iPhone was carrot enough, and, over the next few years, as the iPhone exploded in popularity, the market opportunity afforded by the App Store proved even more attractive. A better analogy to what Apple provided was gas for the fire, particularly with the release of in-app purchase capabilities in 2009. Now developers could offer free versions of their apps and convert consumers down the line, or sell consumables, a very profitable approach for games.
That, though, is where App Store innovation stopped, at least for a while. By 2013, when I started Stratechery, I was wondering Why Doesn’t Apple Enable Sustainable Businesses on the App Store?, by which I meant trials, paid updates, and built-in subscription support. The latter (along with associated trials) finally showed up in 2016, but at that point developer frustration with the App Store had been growing right alongside Apple’s services revenues: productivity apps shared my concerns about sustainability, while “reader” apps like streaming services were frustrated that they couldn’t sign up new users in the app, or even point them to the web; game developers, meanwhile, hated giving away 30% of their revenue.
It’s fair to note that an unacknowledged driver of much of this frustration was surely the fact that the app market matured from the heady days of the early App Store. No one is particularly worried about restrictions or missing capabilities or revenue shares when there is a landgrab for new users’ homescreens; by the end of the decade, though, mature businesses were locked in a zero sum game for user attention and dollars. In that environment the money Apple was taking, despite the fact the lack of flexibility entailed in terms of business model, was much more of an irritant; still, it’s all but impossible for an ongoing business to give up revenue just because they think the arrangement under which they make that revenue is unfair.
The Epic Case
I keep saying “all but impossible” because Epic is the exception that proved the rule: in August 2020 Epic updated Fortnite to include an alternative in-app purchase flow, was subsequently kicked out of the App Store by Apple, and proceeded to file an antitrust lawsuit against the iPhone maker. I documented this saga from beginning to end, including:
- Apple, Epic, and the App Store, which provided a history of the App Store and Epic’s lawsuit at the time it was filed.
- App Store Arguments, which I wrote at the conclusion of the trial, explained why I expected Epic to lose, even as I hoped that Apple would voluntarily make pro-developer changes in the App Store.
- The Apple v. Epic Decision, which reviewed the judge’s decision that favored Apple in 10 of the 11 counts.
The 11th count that Epic prevailed on required Apple to allow developers to steer users to a website to make a purchase; while its implementation was delayed while both parties filed appeals, the lawsuit reached the end of the road last week when the Supreme Court denied certiorari. That meant that Apple had to allow steering, and the company did so in the most restrictive way possible: developers had to use an Apple-granted entitlement to put a link on one screen of their app, and pay Apple 27% of any conversions that happened on the developer’s website within 7 days of clicking said link.
Many developers were outraged, but the company’s tactics were exactly what I expected:
To that end, I wouldn’t be surprised if Apple does the same in this case: developers who steer users to their website may be required to provide auditable conversion numbers and give Apple 27%, and oh-by-the-way, they still have to include an in-app purchase flow (that costs 30% and includes payment processor fees and converts much better). In other words, nothing changes — unless it goes in the other direction: if Apple is going to go to the trouble to build out an auditing arm, then it could very well go after all of the revenue for everyone with an app in the App Store, whether they acquire a user through in-app purchase or not. The reason not to do so before was some combination of goodwill, questionable legality, and most importantly the sheer hassle of it all. At this point, though, it’s not clear if any of those will be deterrents going forward…
Apple has shown, again and again and again, that it is only going to give up App Store revenue kicking-and-screaming; indeed, the company has actually gone the other way, particularly with its crackdown over the last few years on apps that only sold subscriptions on the web (and didn’t include an in-app purchase as well). This is who Apple is, at least when it comes to the App Store.
The crackdown I’m referring to was pure stick: Apple refused to approve upgrades to SaaS apps that had been in the App Store for years unless they added in-app purchase; developers complained but this time the reality of it being impossible for an ongoing business to give up revenue meant they didn’t have any choice but to do extra work so that Apple could have a cut.
Vision Pro’s Missing Apps
The Apple Vision Pro started pre-sales last week, but the biggest surprise came via two stories from Bloomberg. First:
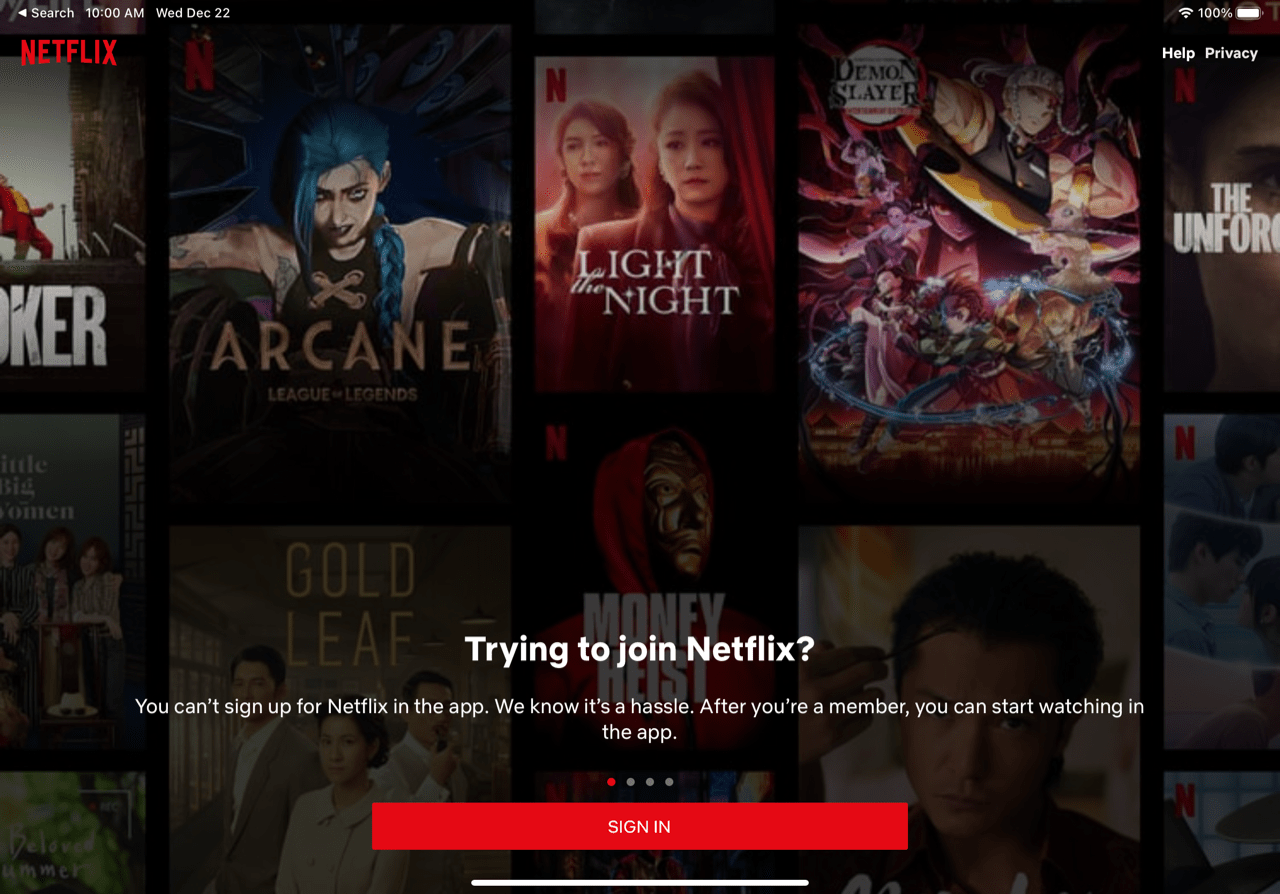
Netflix Inc. isn’t planning to launch an app for Apple Inc.’s upcoming Vision Pro headset, marking a high-profile snub of the new technology by the world’s biggest video subscription service. Rather than designing a Vision Pro app — or even just supporting its existing iPad app on the platform — Netflix is essentially taking a pass. The company, which competes with Apple in streaming, said in a statement that users interested in watching its content on the device can do so from the web.
Google’s YouTube and Spotify Technology SA, the world’s most popular video and music services, are joining Netflix Inc. in steering clear of Apple Inc.’s upcoming mixed-reality headset. YouTube said in a statement Thursday that it isn’t planning to launch a new app for the Apple Vision Pro, nor will it allow its longstanding iPad application to work on the device — at least, for now. YouTube, like Netflix, is recommending that customers use a web browser if they want to see its content: “YouTube users will be able to use YouTube in Safari on the Vision Pro at launch.” Spotify also isn’t currently planning a new app for visionOS — the Vision Pro’s operating system — and doesn’t expect to enable its iPad app to run on the device when it launches, according to a person familiar with matter. But the music service will still likely work from a web browser.
These are a big loss: Malik made the case about why the Vision Pro is the best TV ever, but it will launch without native access to the largest premium streaming service and the largest repository of online video period. I myself am very excited about the productivity use cases of the Vision Pro, which for me includes listening to music while I work; no Spotify makes that harder.
There are, to be sure, valid business reasons for all three services to have not built a native app; the latest prediction from Apple supply chain analyst Ming-Chi Kuo put first-year sales at around 500,000 units, which as a tiny percentage of these services’ user bases may not be worth the investment. Apple’s solution, though, is to simply use a pre-existing iPad app; that all three companies declined to do even that is notable. Nebula CEO Dave Wiskus observed on X:
2003: Steve Jobs brings the big five record labels together in a landmark deal to sell their songs digitally for $0.99 each on the iTunes Store.
2024: Apple can’t convince streaming video companies to check the “allow iPad app” box.
— Dave Wiskus (@dwiskus) January 19, 2024
The Apple Vision Pro app shelves will not be bare in terms of video content; the company says in a press release:
Users will also be able to download and stream TV shows, films, sports, and more with apps from top streaming services, including Disney+, ESPN, NBA, MLB, PGA Tour, Max, Discovery+, Amazon Prime Video, Paramount+, Peacock, Pluto TV, Tubi, Fubo, Crunchyroll, Red Bull TV, IMAX, TikTok, and the 2023 App Store Award-winning MUBI. Users can also watch popular online and streaming video using Safari and other browsers.
It’s not clear how many of these apps are truly native versus iPad apps with the Vision Pro check box, but the absence of Netflix and YouTube do stand out, and their absence is, without question, a total failure for Apple’s developer relations team.
The blame, though, likely goes to the App Store: Apple has been making Netflix in particular jump through hoops for years when it comes to precisely what language the service can or cannot present to customers who can’t sign up in the app, and also can’t be directed to the web. The current version’s language is fairly anondyne (although it has been spicier in the past):

Apple may be unhappy that Netflix viewers have to go to the Netflix website to watch the service on the Vision Pro (and thus can’t download shows for watching offline, like on a plane); Netflix might well point out that that going to the web is exactly what Apple makes Netflix customers do to sign up for the service.1
Developers On Strike
It’s certainly possible that I’m reading too much into these absences: maybe these three companies simply didn’t get enough Visions Pro to build a native app, and felt uncomfortable releasing their iPad versions without knowing how useful they would be. YouTube in particular, given that much of its usage is free, likely has less of a beef with Apple than Netflix or Spotify do, and it’s easy enough to believe that Google just isn’t a company that moves that fast these days.
Still, there’s no question that the biggest beneficiary of these companies being on the Vision Pro — and, correspondingly, the biggest loser from their absence — is Apple. The company is launching an audacious and ambitious new product, and there are major partners in its ecosystem that aren’t interested in helping.
This is the consequence of fashioning App Store policies as a stick: until there is a carrot of a massive user base, it’s hard to see why developers of any size would be particularly motivated to build experiences for the Vision Pro, which will make it that much more difficult to attract said massive user base. Apple was happy to remind users that, when it came to the iPhone, there’s an app for that; in the case of the Vision Pro, there may not be: this is the one and only chance for developers to go on strike without suffering an Epic-like fate, and some of them are taking it.
For now, Apple appears to be so supply-constrained that it doesn’t matter; the company will likely sell as many units as it can make. I would guess that Apple’s strategy with regards to developer hold-outs will be to wait them out, trusting that it can sell enough devices that developers can’t go on strike forever. I certainly think this approach is more likely than offering any sort of concessions to developers, on any of its platforms.
A Disney Double-Down?
The other option may be an even greater investment in content by Apple itself. This could take the form of more Apple TV+ shows and sports deals like MLS, but the most interesting possibility is deepening its partnership with Disney. The entertainment giant is looking for a tech partner to invest in its ESPN streaming service, and the Vision Pro makes Apple a compelling candidate. From an Update last summer:
What does seem notable was Iger’s call out of Apple’s headset; I can attest that the sports experience on the Vision Pro is extraordinary, and remember that Iger appeared on stage at the event to say that Disney would be working with Apple to bring content to the device; here is the sports portion of the video he played at WWDC:
I have to say, one almost gets the impression that the Apple Vision sports-watching experience might have single-handedly convinced Iger to keep ESPN! What does seem likely is that Apple is probably Iger’s preferred partner, and there certainly is upside for Apple — probably more upside than any other tech company — primarily because of the Vision Pro. The single most important factor in the Vision Pro’s success will likely be how quickly entertainment is built for it, and as Cook noted while introducing Iger, “The Walt Disney Company is the world’s leader in entertainment.”
I heard from a lot of people after that Update who were very skeptical that any sort of deal would be struck, in large part because Apple is so difficult to partner with (the company seems continually surprised that not everyone negotiates like the record labels under siege from Napster). And, it should be noted, Disney is showing up on Day One for the Vision Pro launch; why partner if the content is already there?
And yet, Apple’s most potent response to ecosystem intransigence may be to double down: Disney with a war chest (via an Apple partnership) would be a far more formidable competitor to Netflix, and ESPN with a VR camera at every game it televises would, in my estimation, make the Vision Pro an essential purchase for every sports fan. I once argued that Apple Should Buy Netflix the last time the two companies were at odds, but the weakness in that argument is that simply having money another company needs isn’t a compelling enough case; when it comes to Disney the payoff is the Apple Vision Pro having that much more great content that much sooner, not only making the headset a success but also making it impossible for other streaming businesses to not serve their customers just because they think the arrangement under which they operate is unfair.
There is an exception for Netflix specifically: if you download a Netflix game you can sign up with in-app purchase, which the company would almost certainly prefer not to offer but, thanks to Apple’s aforementioned crack-down on SaaS app sign-ups, requires. ↩















{kind=link}